In a comment on my previous post,
visualising Oanda's orderbook, a reader called Darren suggested that I was over complicating things and should perhaps use a more established methodology, namely
Market Profile.
I had heard of Market Profile before Darren mentioned it, but had always assumed that it required access to data that I didn't readily have to hand, i.e. tick level data. With my recent work on
Oanda's API in
Octave that is no longer necessarily the case. However, downloading, storing and manipulating streams of tick data would be a whole new infrastructure project that I would have to implement in either
R or Octave.
Instead of doing this I have done some research into Market Profile and come up with an alternative solution that can use the more readily available tick volume. One of the empirically observed assumptions of Market Profile is that on a "normal" day such volume is normally distributed and creates a "value area" that contains approximately 70% of the market action, which roughly corresponds to action falling within one
standard deviation of the mean of said action, and this mean in turn roughly corresponds with what is termed the "point of control" (POC).
If one takes this at face value as being an accurate description of market action, it is possible to recreate the "normal" market profile with the following Octave code:
ticks = norminv( linspace( 0 , 1 , vol( ii ) + 2 ) , ( high( ii ) + low( ii ) ) / 2 , ( high( ii ) - low( ii ) ) / 6 ) ;
ticks = floor( ticks( 2 : end - 1 ) ./ tick_size .+ tick_size ) .* tick_size ;
[ vals , bin_centres ] = hist( ticks , unique( ticks ) ) ;
What this does is create vol(ii)+2 linearly spaced tick values from 0 to 1, where vol(ii) is the tick volume for an aggregated period, i.e. an ohlc bar, and transforms these into normally distributed ticks with a mean of the midpoint of the bar and an assumed standard deviation of one sixth the high-low range, rounded to the nearest whole tick. The hist function then provides the counts of ticks per level (vals) at levels (bin_centres).
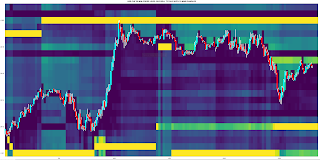
Below is a screen shot of recent EUR_USD forex prices at a resolution of 20 minute candlesticks from 17:00 EST on 28th April 2020 to end of week close at 17:00 EST 1st May 2020.
The silhouette chart at the bottom is the usual tick volume per bar and the horizontal histogram is the Market Profile of the 20 minute bars from the first bar to the first vertical green line, calculated as described above. All the visable vertical green lines represent the open at 07:00 BST, whilst the vertical red lines are the 17:00 EST closes. The horizontal blue line is the current POC at 07:00 BST, taking into account only the bars to the left of the first green line, i.e. the Asian overnight session.
Next is a video of the progression through time along the above chart:
as time progesses the Market Profile histogram changes and new, blue POC lines are
plotted, with the time progression being marked by the advancing green lines. During subsequent Asian sessions the histogram colour is plotted
in red, and new POC lines formed in the Asian session are also plotted
in red.
For easier viewing, this is a screen shot of the chart as it appears at the end of the video
For comparative purposes this is a screen shot of the same as above, but using 10 minute ohlc bars and 10 minute updates to the Market Profile
Readers should note that the scaling of the silhouette charts and histograms are not the same for both - they are hand scaled by me for visualisation purposes only.
For completeness, here is the Octave script used to produce the above
clear all ;
pkg load statistics ;
## load data
cd /home/dekalog/Documents/octave/oanda_data/20m ;
oanda_files_20m = glob( "*_ohlc_20m" ) ;
ix = 7 ;##input( 'Tradable? ' ) ;
data = dlmread( oanda_files_20m{ ix } ) ;
data( 1 : 146835 , : ) = [] ;
tick_size = 0.0001 ;
open = data( : , 18 ) ; high = data( : , 19 ) ; low = data( : , 20 ) ; close = data( : , 21 ) ; vol = data( : , 22 ) ;
## Create grid for day
max_high = max( high ) + 0.001 ; min_low = min( low ) - 0.001 ; grid = ( min_low : tick_size : max_high + 0.0001 ) ;
grid_ix = floor( grid ./ tick_size .+ tick_size ) .* tick_size ;
market_profile = [ grid_ix ; zeros( 1 , size( grid_ix , 2 ) ) ] ;
asian_market_profile = [ grid_ix ; zeros( 1 , size( grid_ix , 2 ) ) ] ;
figure( 20 ) ;
candle( high , low , close , open ) ;
vline( 27 , 'g' ) ; vline( 72 , 'r' ) ; vline( 99 , 'g' ) ; vline( 144 , 'r' ) ; vline( 174 , 'g' ) ;
xlim( [ 0 size( open , 1 ) ] ) ;
ylim( [ grid_ix(1) grid_ix(end) ] ) ;
hold on ; plot( ( vol .* 0.0000004 ) .+ grid_ix( 1 ) , 'b' , 'linewidth' , 2 ) ;
area( ( vol .* 0.0000004 ) .+ grid_ix( 1 ) , 'facecolor' , 'b' ) ; hold off ;
for ii = 1 : 27
ticks = norminv( linspace( 0 , 1 , vol( ii ) + 2 ) , ( high( ii ) + low( ii ) ) / 2 , ( high( ii ) - low( ii ) ) / 6 ) ;
ticks = floor( ticks( 2 : end - 1 ) ./ tick_size .+ tick_size ) .* tick_size ;
[ vals , bin_centres ] = hist( ticks , unique( ticks ) ) ;
vals_ix = find( ismember( grid_ix , bin_centres ) ) ;
market_profile( 2 , vals_ix ) += vals ;
endfor
[ max_mp_val_old , max_mp_ix ] = max( market_profile( 2 , : ) ) ;
hold on ; figure( 20 ) ; H = barh( market_profile( 1 , : ) , market_profile( 2 , : ).*0.005 , 'c' ) ; hold off ;
hline( market_profile( 1 , max_mp_ix ) , 'b' ) ;
for ii = 28 : 72
ticks = norminv( linspace( 0 , 1 , vol( ii ) + 2 ) , ( high( ii ) + low( ii ) ) / 2 , ( high( ii ) - low( ii ) ) / 6 ) ;
ticks = floor( ticks( 2 : end - 1 ) ./ tick_size .+ tick_size ) .* tick_size ;
vals = hist( ticks , unique( ticks ) ) ;
vals_ix = find( ismember( grid_ix , unique( ticks ) ) ) ;
market_profile( 2 , vals_ix ) += vals ;
[ max_mp_val , max_mp_ix ] = max( market_profile( 2 , : ) ) ;
hold on ; figure( 20 ) ; barh( market_profile( 1 , : ) , market_profile( 2 , : ).*0.005 , 'c' ) ; hold off ;
vline( ii , 'g' ) ;
if ( max_mp_val > max_mp_val_old )
hline( market_profile( 1 , max_mp_ix ) , 'b' ) ;
max_mp_val_old = max_mp_val ;
endif
pause(0.01) ;
endfor
for ii = 73 : 99
ticks = norminv( linspace( 0 , 1 , vol( ii ) + 2 ) , ( high( ii ) + low( ii ) ) / 2 , ( high( ii ) - low( ii ) ) / 6 ) ;
ticks = floor( ticks( 2 : end - 1 ) ./ tick_size .+ tick_size ) .* tick_size ;
vals = hist( ticks , unique( ticks ) ) ;
vals_ix = find( ismember( grid_ix , unique( ticks ) ) ) ;
market_profile( 2 , vals_ix ) += vals ;
asian_market_profile( 2 , vals_ix ) += vals ;
[ max_mp_val , max_mp_ix ] = max( market_profile( 2 , : ) ) ;
hold on ; figure( 20 ) ; barh( market_profile( 1 , : ) , market_profile( 2 , : ).*0.005 , 'c' ) ;
figure( 20 ) ; barh( asian_market_profile( 1 , : ) , asian_market_profile( 2 , : ).*0.005 , 'r' ) ;
hold off ;
vline( ii , 'g' ) ;
if ( max_mp_val > max_mp_val_old )
hline( market_profile( 1 , max_mp_ix ) , 'b' ) ;
max_mp_val_old = max_mp_val ;
endif
pause(0.01) ;
endfor
[ ~ , max_mp_ix ] = max( asian_market_profile( 2 , : ) ) ;
hline( asian_market_profile( 1 , max_mp_ix ) , 'r' ) ;
for ii = 100 : 144
ticks = norminv( linspace( 0 , 1 , vol( ii ) + 2 ) , ( high( ii ) + low( ii ) ) / 2 , ( high( ii ) - low( ii ) ) / 6 ) ;
ticks = floor( ticks( 2 : end - 1 ) ./ tick_size .+ tick_size ) .* tick_size ;
vals = hist( ticks , unique( ticks ) ) ;
vals_ix = find( ismember( grid_ix , unique( ticks ) ) ) ;
market_profile( 2 , vals_ix ) += vals ;
[ max_mp_val , max_mp_ix ] = max( market_profile( 2 , : ) ) ;
hold on ; figure( 20 ) ; barh( market_profile( 1 , : ) , market_profile( 2 , : ).*0.005 , 'c' ) ;
figure( 20 ) ; barh( asian_market_profile( 1 , : ) , asian_market_profile( 2 , : ).*0.005 , 'r' ) ;
hold off ;
vline( ii , 'g' ) ;
if ( max_mp_val > max_mp_val_old )
hline( market_profile( 1 , max_mp_ix ) , 'b' ) ;
max_mp_val_old = max_mp_val ;
endif
pause(0.01) ;
endfor
[ max_mp_val , max_mp_ix ] = max( market_profile( 2 , 101 : end ) ) ;
max_mp_val_old = max_mp_val ;
hline( market_profile( 1 , max_mp_ix + 100 ) , 'b' ) ;
for ii = 145 : 174
ticks = norminv( linspace( 0 , 1 , vol( ii ) + 2 ) , ( high( ii ) + low( ii ) ) / 2 , ( high( ii ) - low( ii ) ) / 6 ) ;
ticks = floor( ticks( 2 : end - 1 ) ./ tick_size .+ tick_size ) .* tick_size ;
vals = hist( ticks , unique( ticks ) ) ;
vals_ix = find( ismember( grid_ix , unique( ticks ) ) ) ;
market_profile( 2 , vals_ix ) += vals ;
asian_market_profile( 2 , vals_ix ) += vals ;
[ max_mp_val , max_mp_ix ] = max( market_profile( 2 , 101 : end ) ) ;
hold on ; figure( 20 ) ; barh( market_profile( 1 , : ) , market_profile( 2 , : ).*0.005 , 'c' ) ;
figure( 20 ) ; barh( asian_market_profile( 1 , : ) , asian_market_profile( 2 , : ).*0.005 , 'r' ) ;
hold off ;
vline( ii , 'g' ) ;
if ( max_mp_val > max_mp_val_old )
hline( market_profile( 1 , max_mp_ix + 100 ) , 'b' ) ;
max_mp_val_old = max_mp_val ;
endif
pause(0.01) ;
endfor
[ ~ , max_mp_ix ] = max( asian_market_profile( 2 , 101 : end ) ) ;
hline( asian_market_profile( 1 , max_mp_ix + 100 ) , 'r' ) ;
for ii = 175 : size( open , 1 )
ticks = norminv( linspace( 0 , 1 , vol( ii ) + 2 ) , ( high( ii ) + low( ii ) ) / 2 , ( high( ii ) - low( ii ) ) / 6 ) ;
ticks = floor( ticks( 2 : end - 1 ) ./ tick_size .+ tick_size ) .* tick_size ;
vals = hist( ticks , unique( ticks ) ) ;
vals_ix = find( ismember( grid_ix , unique( ticks ) ) ) ;
market_profile( 2 , vals_ix ) += vals ;
[ max_mp_val , max_mp_ix ] = max( market_profile( 2 , 101 : end ) ) ;
hold on ; figure( 20 ) ; barh( market_profile( 1 , : ) , market_profile( 2 , : ).*0.005 , 'c' ) ;
figure( 20 ) ; barh( asian_market_profile( 1 , : ) , asian_market_profile( 2 , : ).*0.005 , 'r' ) ;
hold off ;
vline( ii , 'g' ) ;
if ( max_mp_val > max_mp_val_old )
hline( market_profile( 1 , max_mp_ix + 100 ) , 'b' ) ;
max_mp_val_old = max_mp_val ;
endif
pause(0.01) ;
endfor
As just noted above for the scaling of the charts/video, readers should also be aware that within this script there are a lot of
magic numbers that are unique to the data and scaling being used; therefore, this is not a plug in and play video script.
My thanks to the reader Darren, who suggested that I look into Market Profile. More in due course.