Further to my previous post, below is an extended version of the "blurred_maxshift_1d_linear" function. This updated version has two extra outputs: a vector of the cluster centre index ix values and a vector the same length as the input data with the cluster centres to which each datum has been assigned. These changes have necessitated some extensive re-writing of the function to include various checks contained in nested conditional statements.
## Copyright (C) 2020 dekalog
##
## This program is free software: you can redistribute it and/or modify it
## under the terms of the GNU General Public License as published by
## the Free Software Foundation, either version 3 of the License, or
## (at your option) any later version.
##
## This program is distributed in the hope that it will be useful, but
## WITHOUT ANY WARRANTY; without even the implied warranty of
## MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
## GNU General Public License for more details.
##
## You should have received a copy of the GNU General Public License
## along with this program. If not, see
## .
## -*- texinfo -*-
## @deftypefn {} {@var{train_vec}, @var{cluster_centre_ix}, @var{assigned_cluster_centre_ix} =} blurred_maxshift_1d_linear_V2 (@var{train_vec}, @var{bandwidth})
##
## @seealso{}
## @end deftypefn
## Author: dekalog
## Created: 2020-10-21
function [ new_train_vec , cluster_centre_ix , assigned_cluster_centre_ix ] = blurred_maxshift_1d_linear_V2 ( train_vec , bandwidth )
if ( nargin < 2 )
bandwidth = 1 ;
endif
if ( numel( train_vec ) < 2 * bandwidth + 1 )
error( 'Bandwidth too wide for length of train_vec.' ) ;
endif
length_train_vec = numel( train_vec ) ;
new_train_vec = zeros( size( train_vec ) ) ;
assigned_cluster_centre_ix = ( 1 : 1 : length_train_vec ) ;
## initialising loop
## do the beginning
[ ~ , ix ] = max( train_vec( 1 : 2 * bandwidth + 1 ) ) ;
new_train_vec( ix ) = sum( train_vec( 1 : bandwidth + 1 ) ) ;
assigned_cluster_centre_ix( 1 : bandwidth + 1 ) = ix ;
## and end of train_vec first
[ ~ , ix ] = max( train_vec( end - 2 * bandwidth : end ) ) ;
new_train_vec( end - 2 * bandwidth - 1 + ix ) = sum( train_vec( end - bandwidth : end ) ) ;
assigned_cluster_centre_ix( end - bandwidth : end ) = length_train_vec - 2 * bandwidth - 1 + ix ;
for ii = ( bandwidth + 2 ) : ( length_train_vec - bandwidth - 1 )
[ ~ , ix ] = max( train_vec( ii - bandwidth : ii + bandwidth ) ) ;
new_train_vec( ii - bandwidth - 1 + ix ) += train_vec( ii ) ;
assigned_cluster_centre_ix( ii ) = ii - bandwidth - 1 + ix ;
endfor
## end of initialising loop
train_vec = new_train_vec ;
## initialise the while condition variable
has_converged = 0 ;
while ( has_converged < 1 )
new_train_vec = zeros( size( train_vec ) ) ;
## do the beginning
[ ~ , ix ] = max( train_vec( 1 : 2 * bandwidth + 1 ) ) ;
new_train_vec( ix ) += sum( train_vec( 1 : bandwidth + 1 ) ) ;
assigned_cluster_centre_ix( 1 : bandwidth + 1 ) = ix ;
## and end of train_vec first
[ ~ , ix ] = max( train_vec( end - 2 * bandwidth : end ) ) ;
new_train_vec( end - 2 * bandwidth - 1 + ix ) += sum( train_vec( end - bandwidth : end ) ) ;
assigned_cluster_centre_ix( end - bandwidth : end ) = length_train_vec - 2 * bandwidth - 1 + ix ;
for ii = ( bandwidth + 2 ) : ( length_train_vec - bandwidth - 1 )
[ max_val , ix ] = max( train_vec( ii - bandwidth : ii + bandwidth ) ) ;
## check for ties in max_val value in window
no_ties = sum( train_vec( ii - bandwidth : ii + bandwidth ) == max_val ) ;
if ( no_ties == 1 && max_val == train_vec( ii ) && ix == bandwidth + 1 ) ## main if
## value in train_vec(ii) is max val of window, with no ties
new_train_vec( ii ) += train_vec( ii ) ;
assigned_cluster_centre_ix( ii ) = ii ;
elseif ( no_ties == 1 && max_val != train_vec( ii ) && ix != bandwidth + 1 ) ## main if
## no ties for max_val, but need to move data at ii and change ix
## get assigned_cluster_centre_ix that point to ii, which needs to be updated
assigned_ix = find( assigned_cluster_centre_ix == ii ) ;
if ( !isempty( assigned_ix ) ) ## should always be true because at least the one original ii == ii
assigned_cluster_centre_ix( assigned_ix ) = ii - ( bandwidth + 1 ) + ix ;
elseif ( isempty( assigned_ix ) ) ## but cheap insurance
assigned_cluster_centre_ix( ii ) = ii - ( bandwidth + 1 ) + ix ;
endif
new_train_vec( ii - ( bandwidth + 1 ) + ix ) += train_vec( ii ) ;
elseif ( no_ties > 1 && max_val > train_vec( ii ) ) ## main if
## 2 ties for max_val, which is > val at ii, need to move data at ii
## to the closer max_val ix and change ix in assigned_cluster_centre_ix
match_max_val_ix = find( train_vec( ii - bandwidth : ii + bandwidth ) == max_val ) ;
if ( numel( match_max_val_ix ) == 2 ) ## only 2 matching max vals
centre_window_dist = ( bandwidth + 1 ) .- match_max_val_ix ;
if ( abs( centre_window_dist( 1 ) ) == abs( centre_window_dist( 2 ) ) )
## equally distant from centre ii of moving window
assigned_ix = find( assigned_cluster_centre_ix == ii ) ;
if ( !isempty( assigned_ix ) ) ## should always be true because at least the one original ii == ii
ix_before = find( assigned_ix < ii ) ;
ix_after = find( assigned_ix > ii ) ;
new_train_vec( ii - ( bandwidth + 1 ) + match_max_val_ix( 1 ) ) += train_vec( ii ) / 2 ;
new_train_vec( ii - ( bandwidth + 1 ) + match_max_val_ix( 2 ) ) += train_vec( ii ) / 2 ;
assigned_cluster_centre_ix( assigned_ix( ix_before ) ) = ii - ( bandwidth + 1 ) + match_max_val_ix( 1 ) ;
assigned_cluster_centre_ix( assigned_ix( ix_after ) ) = ii - ( bandwidth + 1 ) + match_max_val_ix( 2 ) ;
assigned_cluster_centre_ix( ii ) = ii ; ## bit of a kluge
elseif ( isempty( assigned_ix ) ) ## but cheap insurance
## no other assigned_cluster_centre_ix values to account for, so just split equally
new_train_vec( ii - ( bandwidth + 1 ) + match_max_val_ix( 1 ) ) += train_vec( ii ) / 2 ;
new_train_vec( ii - ( bandwidth + 1 ) + match_max_val_ix( 2 ) ) += train_vec( ii ) / 2 ;
assigned_cluster_centre_ix( ii ) = ii ; ## bit of a kluge
else
error( 'There is an unknown error in instance ==2 matching max_vals with equal distances to centre of moving window with assigned_ix. Write code to deal with this edge case.' ) ;
endif
else ## not equally distant from centre ii of moving window
assigned_ix = find( assigned_cluster_centre_ix == ii ) ;
if ( !isempty( assigned_ix ) ) ## should always be true because at least the one original ii == ii
## There is an instance == 2 matching max_vals with non equal distances to centre of moving window with previously assigned_ix to ii ix
## Assign all assigned_ix to the nearest max value ix
[ ~ , min_val_ix ] = min( [ abs( centre_window_dist( 1 ) ) abs( centre_window_dist( 2 ) ) ] ) ;
new_train_vec( ii - ( bandwidth + 1 ) + match_max_val_ix( min_val_ix ) ) += train_vec( ii ) ;
assigned_cluster_centre_ix( ii ) = ii - ( bandwidth + 1 ) + match_max_val_ix( min_val_ix ) ;
assigned_cluster_centre_ix( assigned_ix ) = ii - ( bandwidth + 1 ) + match_max_val_ix( min_val_ix ) ;
elseif ( isempty( assigned_ix ) ) ## but cheap insurance
[ ~ , min_val_ix ] = min( abs( centre_window_dist ) ) ;
new_train_vec( ii - ( bandwidth + 1 ) + match_max_val_ix( min_val_ix ) ) += train_vec( ii ) ;
assigned_cluster_centre_ix( ii ) = ii - ( bandwidth + 1 ) + match_max_val_ix( min_val_ix ) ;
else
error( 'There is an unknown error in instance of ==2 matching max_vals with unequal distances. Write the code to deal with this edge case.' ) ;
endif
endif ##
elseif ( numel( match_max_val_ix ) > 2 ) ## There is an instance of >2 matching max_vals.
## There must be one max val closer than the others or two equally close
centre_window_dist = abs( ( bandwidth + 1 ) .- match_max_val_ix ) ;
centre_window_dist_min = min( centre_window_dist ) ;
centre_window_dist_min_ix = find( centre_window_dist == centre_window_dist_min ) ;
if ( numel( centre_window_dist_min_ix ) == 1 ) ## there is one closet ix
assigned_ix = find( assigned_cluster_centre_ix == ii ) ;
if ( !isempty( assigned_ix ) ) ## should always be true because at least the one original ii == ii
new_train_vec( ii - ( bandwidth + 1 ) + centre_window_dist_min_ix ) += train_vec( ii ) ;
assigned_cluster_centre_ix( ii ) = ii - ( bandwidth + 1 ) + centre_window_dist_min_ix ;
assigned_cluster_centre_ix( assigned_ix ) = ii - ( bandwidth + 1 ) + centre_window_dist_min_ix ;
elseif ( isempty( assigned_ix ) ) ## but cheap insurance
new_train_vec( ii - ( bandwidth + 1 ) + centre_window_dist_min_ix ) += train_vec( ii ) ;
assigned_cluster_centre_ix( ii ) = ii - ( bandwidth + 1 ) + centre_window_dist_min_ix ;
endif
elseif ( numel( centre_window_dist_min_ix ) == 2 ) ## there are 2 equally close ix
assigned_ix = find( assigned_cluster_centre_ix == ii ) ;
if ( !isempty( assigned_ix ) ) ## should always be true because at least the one original ii == ii
ix_before = find( assigned_ix < ii ) ;
ix_after = find( assigned_ix > ii ) ;
new_train_vec( ii - ( bandwidth + 1 ) + centre_window_dist_min_ix( 1 ) ) += train_vec( ii ) / 2 ;
new_train_vec( ii - ( bandwidth + 1 ) + centre_window_dist_min_ix( 2 ) ) += train_vec( ii ) / 2 ;
assigned_cluster_centre_ix( assigned_ix( ix_before ) ) = ii - ( bandwidth + 1 ) + centre_window_dist_min_ix( 1 ) ;
assigned_cluster_centre_ix( assigned_ix( ix_after ) ) = ii - ( bandwidth + 1 ) + centre_window_dist_min_ix( 2 ) ;
assigned_cluster_centre_ix( ii ) = ii ; ## bit of a kluge
elseif ( isempty( assigned_ix ) ) ## but cheap insurance
## no other assigned_cluster_centre_ix values to account for, so just split equally
new_train_vec( ii - ( bandwidth + 1 ) + centre_window_dist_min_ix( 1 ) ) += train_vec( ii ) / 2 ;
new_train_vec( ii - ( bandwidth + 1 ) + centre_window_dist_min_ix( 2 ) ) += train_vec( ii ) / 2 ;
assigned_cluster_centre_ix( ii ) = ii ; ## bit of a kluge
endif
else
error( 'Unknown error in numel( match_max_val_ix ) > 2.' ) ;
endif
##error( 'There is an instance of >2 matching max_vals. Write the code to deal with this edge case.' ) ;
else
error( 'There is an unknown error in instance of >2 matching max_vals. Write the code to deal with this edge case.' ) ;
endif
endif ## main if end
endfor
if ( sum( ( train_vec == new_train_vec ) ) == length_train_vec )
has_converged = 1 ;
else
train_vec = new_train_vec ;
endif
endwhile
cluster_centre_ix = unique( assigned_cluster_centre_ix ) ;
cluster_centre_ix( cluster_centre_ix == 0 ) = [] ;
endfunction
The reason for this re-write was to accommodate a cross validation routine, which is described in the paper Cluster Validation by Prediction Strength, and a simple outline of which is given in this stackexchange.com answer.
My Octave code implementation of this is shown in the code box below. This is not exactly as described in the above paper because the number of clusters, K, is not exactly specified due to the above function automatically determining K based on the data. The routine below is perhaps more accurately described as being inspired by the original paper.
## create train and test data sets
########## UNCOMMENT AS NECESSARY #####
time_ix = [ 1 : 198 ] ; ## Monday
##time_ix = [ 115 : 342 ] ; ## Tuesday
##time_ix = [ 259 : 486 ] ; ## Wednesday
##time_ix = [ 403 : 630 ] ; ## Thursday
##time_ix = [ 547 : 720 ] ; ## Friday
##time_ix = [ 1 : 720 ] ; ## all data
#######################################
all_cv_solutions = zeros( size( data_matrix , 3 ) , size( data_matrix , 3 ) ) ;
n_iters = 1 ;
for iter = 1 : n_iters ## related to # of rand_ix sets generated
rand_ix = randperm( size( data_matrix , 1 ) ) ;
train_ix = rand_ix( 1 : round( numel( rand_ix ) * 0.5 ) ) ;
test_ix = rand_ix( round( numel( rand_ix ) * 0.5 ) + 1 : end ) ;
train_data_matrix = sum( data_matrix( train_ix , time_ix , : ) ) ;
test_data_matrix = sum( data_matrix( test_ix , time_ix , : ) ) ;
all_proportions_indicated = zeros( 1 , size( data_matrix , 3 ) ) ;
for cv_ix = 1 : size( data_matrix , 3 ) ; ## related to delta_turning_point_filter n_bar parameter
for bandwidth = 1 : size( data_matrix , 3 )
## train set clustering
if ( bandwidth == 1 )
[ train_out , cluster_centre_ix_train , assigned_cluster_centre_ix_train ] = blurred_maxshift_1d_linear_V2( train_data_matrix(:,:,cv_ix) , bandwidth ) ;
elseif( bandwidth > 1 )
[ train_out , cluster_centre_ix_train , assigned_cluster_centre_ix_train ] = blurred_maxshift_1d_linear_V2( train_out , bandwidth ) ;
endif
train_out_pairs_mat = zeros( numel( assigned_cluster_centre_ix_train ) , numel( assigned_cluster_centre_ix_train ) ) ;
for ii = 1 : numel( cluster_centre_ix_train )
cc_ix = find( assigned_cluster_centre_ix_train == cluster_centre_ix_train( ii ) ) ;
train_out_pairs_mat( cc_ix , cc_ix ) = 1 ;
endfor
train_out_pairs_mat = triu( train_out_pairs_mat , 1 ) ; ## get upper diagonal matrix
## test set clustering
if ( bandwidth == 1 )
[ test_out , cluster_centre_ix_test , assigned_cluster_centre_ix_test ] = blurred_maxshift_1d_linear_V2( test_data_matrix(:,:,cv_ix) , bandwidth ) ;
elseif( bandwidth > 1 )
[ test_out , cluster_centre_ix_test , assigned_cluster_centre_ix_test ] = blurred_maxshift_1d_linear_V2( test_out , bandwidth ) ;
endif
all_test_out_pairs_mat = zeros( numel( assigned_cluster_centre_ix_test ) , numel( assigned_cluster_centre_ix_test ) ) ;
test_out_pairs_clusters_proportions = ones( 1 , numel( cluster_centre_ix_test ) ) ;
for ii = 1 : numel( cluster_centre_ix_test )
cc_ix = find( assigned_cluster_centre_ix_test == cluster_centre_ix_test( ii ) ) ;
all_test_out_pairs_mat( cc_ix , cc_ix ) = 1 ;
test_out_pairs_mat = all_test_out_pairs_mat( cc_ix , cc_ix ) ;
test_out_pairs_mat = triu( test_out_pairs_mat , 1 ) ; ## get upper diagonal matrix
test_out_pairs_mat_sum = sum( sum( test_out_pairs_mat ) ) ;
if ( test_out_pairs_mat_sum > 0 )
test_out_pairs_clusters_proportions( ii ) = sum( sum( train_out_pairs_mat( cc_ix , cc_ix ) .* test_out_pairs_mat ) ) / ...
test_out_pairs_mat_sum ;
endif
endfor
all_proportions_indicated( bandwidth ) = min( test_out_pairs_clusters_proportions ) ;
all_cv_solutions( bandwidth , cv_ix ) += all_proportions_indicated( bandwidth ) ;
endfor ## bandwidth for loop
endfor ## end of cv_ix loop
endfor ## end of iter for
all_cv_solutions = all_cv_solutions ./ n_iters ;
surf( all_cv_solutions ) ; xlabel( 'BANDWIDTH' , 'fontsize' , 20 ) ; ylabel( 'CV IX' , 'fontsize' , 20 ) ;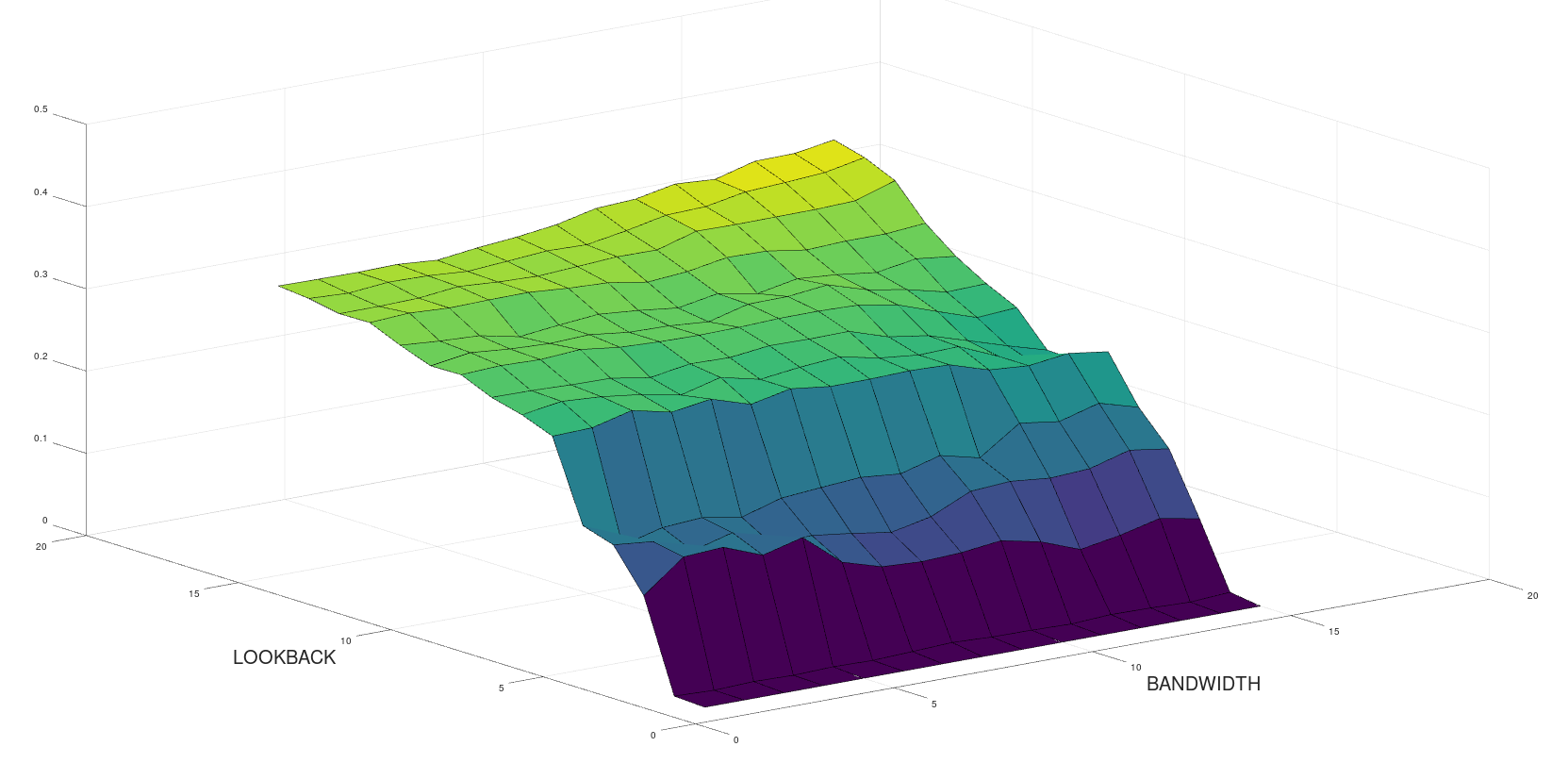
The "bandwidth" plotted along the front edge of the surface plot is one of the input parameters to the "blurred_maxshift_1d_linear" function, whilst the "lookback" is a parameter of the original data generating function which identifies local highs and lows in a price time series. There appears to be a distinct "elbow" at "lookback" = 6 which is more or less consistent for all values of "bandwidth." Since the underlying data for this is 10 minute OHLC bars, the ideal "lookback" would, therefore, appear to be on the hourly timeframe.
However, having spent some considerable time and effort to get the above working satisfactorily, I am now not so sure that I'll actually use the above code. The reason for this is shown in the following animated GIF.

This shows K segmentation of the exact same data used above, from K = 1 to 19 inclusive, using R and its Ckmeans.1d.dp package, with vignette tutorial here. I am particularly attracted to this because of its speed, compared to my code above, as well as its guarantees with regard to optimality and reproducability. If one stares at the GIF for long enough one can see possible, significant clusters at index values (x-axis) which correspond, approximately, to particularly significant times such as London and New York market opening and closing times: ix = 55, 85, 115 and 145.
More about this in my next post.
No comments:
Post a Comment